

La Dendrio credem ca Industria 4.0 se bazeaza, in mare masura, pe evolutiile tehnologice din domeniile Cloud Computing si Machine Learning. Era digitalizarii implica reducerea costurilor, imbunatatirea securitatii sistemelor IT si automatizarea unor procese care pana acum erau executate manual.
Din perspectiva mea, consider ca domeniul IT se va baza cat mai curand pe inteligenta artificiala aplicata in majoritatea niselor pentru a putea ajuta un sistem sa invete automat anumite task-uri sau sa extraga informatii pretioase folosind tehnici de Machine Learning. Aceste tehnici sunt fundamentate prin algoritmi matematici care creeaza modele inteligente, capabile sa evolueze pe baza unor date de intrare cunoscute care modeleaza probleme reale.
Companiile IT apeleaza la inovatie prin Machine Learning pentru a obtine sisteme care sa invete autonom intr-un mod supervizat (Stocks Prediction, Forensics, Fraud Detection, Audio-Video Classification), nesupervizat (Big Data, sisteme de recomandare, Clustering) sau prin evolutia unui agent intern bazat pe recompense (Reinforcement Learning, Gaming). Astfel de solutii ne afecteaza in mod direct business-ul si agilitatea cu care putem colabora cu partenerii.
AWS este unul dintre partenerii nostri provideri de cloud si ne propune o multitudine de sisteme si servicii prin care putem dezvolta aplicatii bazate pe Machine Learning, oferind posibilitatea de a alege unul dintre modelele IaaS sau PaaS in functie de gestiunea si accesul dorit.
Folosind modelul IaaS arhitectii si inginerii de retele pot avea control asupra infrastructurii IT a aplicatiilor tale: gestiunea sistemelor de operare, a nivelelor de runtime, middleware, a securitatii in cadrul cloud-ului, dar si accesul la nivelul aplicatiei si a datelor. Elementele de infrastructura fizica(virtualizare, stocare, servere sau networking) sunt gestionate de AWS sub un anumit SLA pe care ni-l ofera. Un exemplu de model IaaS poate consta in rularea unor algoritmi de predictie a vremii pentru anul 2021 in limbajul de programare Python pe instante de tip EC2.
Eu prefer modelul PaaS unde pot incarca intregul cod al aplicatiei fara a fi nevoit sa configurez sau sa monitorizez infrastructura. AWS provizioneaza capacitatea de resurse necesara rularii aplicatiei mele, avand in vedere scalarea si interconectarea subsistemelor adiacente. Un serviciu de tip PaaS orientat catre Machine Learning, oferit de AWS, este Amazon SageMaker. Utilizatorii trebuie sa creeze un tip de arhivare a artefactelor de model sau un container ce implica un framework de ML si sa incarce aceste modele intr-un mod de stocare Amazon S3, respectiv Amazon ECR (Elastic Container Registry), vezi Fig. 1.
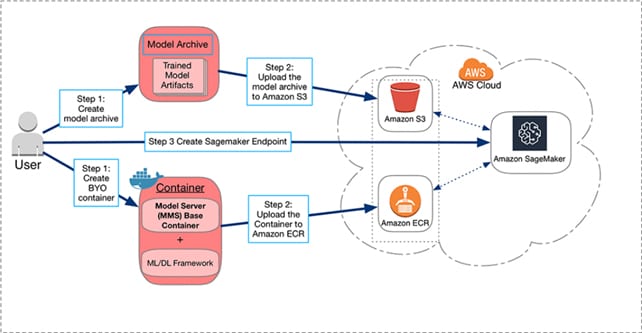
Fig. 1. – Amazon SageMaker Flow
In final, se aloca un endpoint SageMaker ce va prelua toate datele si codul incarcat in IDE-ul oferit de SageMaker.
Recomand dezvoltarea aplicatiilor inteligente cu ajutorul limbajului de programare Python si a librariilor aferente, PyTorch, Tensorflow, pentru care exista o mare comunitate ce investeste in software si documentatii de tip open-source. Daca nu esti insa, confortabil cu acest stack, poti folosi orice alta abordare pentru care AWS iti ofera suport si framework-uri prin AWS SDK(Go, Java, .Net Core, C#, etc.).
Exemplele pe care le-am propus au la baza un model de cloud public, dar exista solutii de integrare si pentru cloud-ul hybrid sau privat.
Cea de-a doua saptamana alocata evenimentului AWS re:Invent 2020 a fost dedicata inovatiei prin Machine Learning si AI si a fost deschisa printr-un keynote legat de ecosistemul Amazon SageMaker si noile caracteristici dezvoltate de AWS in 2020.
M-a surprins in mod placut faptul ca AWS investeste puternic in sisteme ce implica tehnologii de ultima generatie care sunt solicitate de piata IT globala.
Tehnicile ML pornesc cu un set de date care sa descrie mediul asupra caruia se vor aplica algoritmii. Prin acest set de date, pot incearca sa descriu un fenomen, o problema reala ce poate fi rezolvata inteligent pornind de la un mediu initial. Setul de date reale este impartit in doua subseturi: antrenare si testare cu proportiile 80%, respectiv 20%. Setul de antrenare este solicitat de algoritm pentru a obtine un model teoretic care sa descrie o problema, iar asupra setului de testare se aplica modelul antrenat. Setul de testare ofera o metrica(o eroare) pe baza careia pot decide daca modelul este unul bun. Cum astfel de algoritmi necesita volume foarte mari de date pentru a descrie corect un mediu, modelul este predispus unor abateri logice “bias”, date de lipsa unei cantitati suficiente de date.
Cred ca tehnologiile bazate pe inteligenta artificiala vor impacta puternic proiectele din domeniul IT in viitorul apropiat. Am intalnit in aplicatiile mele erori de tip bias si pot fi foarte greu de depistat si corectat.
Am aflat in cadrul evenimentului ca AWS propune un nou feature legat de Amazon SageMaker care sa rezolve problema bias-ului, Clarify. Cu acest serviciu poti detecta abateri de la modelul real atat in timpul pregatirii setului de date, dupa obtinerea modelului antrenat dar si dupa implementarea modelului final. SageMaker Clarify dispune de filtre, imagini si grafice pe baza carora poti obtine detalii ce te vor ajuta sa alegi urmatoarele decizii in dezvoltarea aplicatiei, vezi Fig. 2.
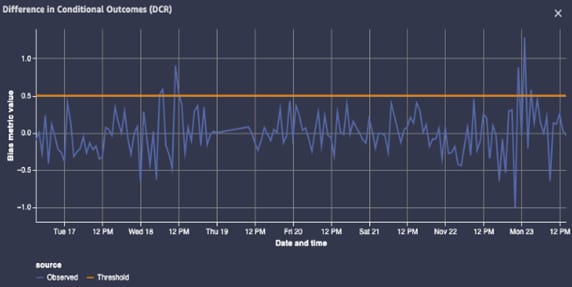
Bias metric value Threshold in Amazon SageMaker Clarify
Serviciul meu preferat din AWS este AWS Lambda. Acesta imi ofera posibilitatea de a ma focusa pe codul aplicatiei mele, provider-ul ocupandu-se de administrarea infrastructurii si platesc doar pe perioada in care codul ruleaza. Am folosit pentru prima data acest serviciu pentru a crea o aplicatie care ma avertiza ca am depasit resursele Free Tier si deprovisiona masinile active.
Amazon SageMaker Clarify poate fi integrat nativ cu serviciul de monitorizare Amazon CloudWatch cu care pot genera alarme iar cu ajutorul serviciului AWS Lambda pot scrie o functie Python in care sa tratez fiecare eveniment aparut.
Robert Simion
{kind=link}